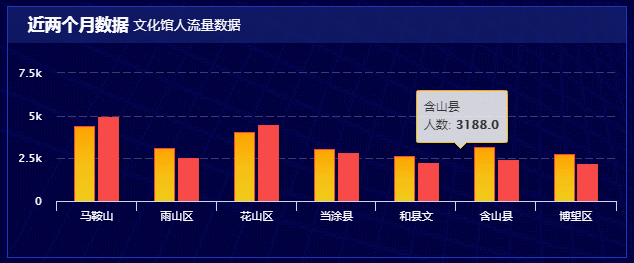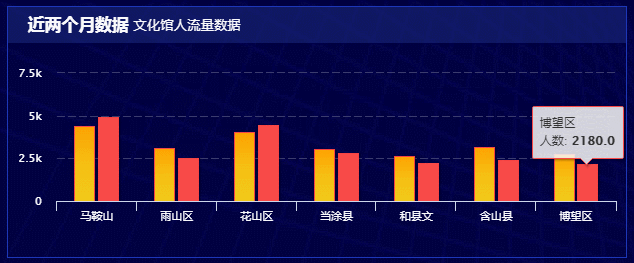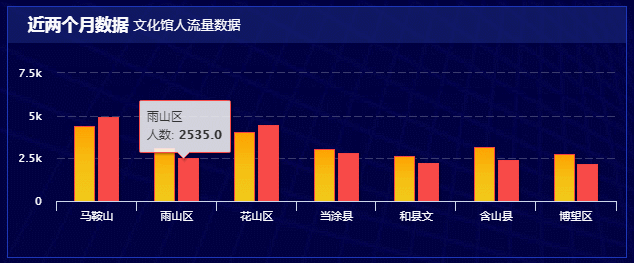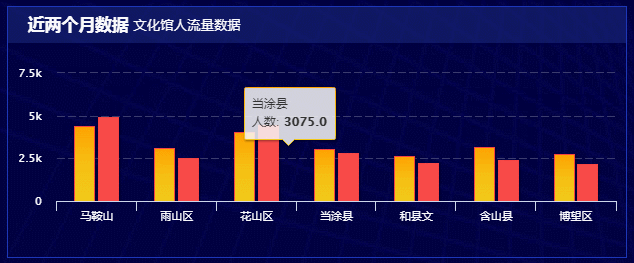
技术站:
vue、vue-router、vuex、webpack;
基于微信扫一扫页面:
扫描预览:


路走了28年,方向始终不变。
npm install === yarn —— install 安装是默认行为。
npm install taco --save === yarn add taco —— taco 包立即被保存到 package.json 中。
npm uninstall taco --save === yarn remove taco
在 npm 中,可以使用 npm config set save true 设置 — -save 为默认行为,但这对多数开发者而言并非显而易见的。在 yarn 中,在package.json 中添加(add)和移除(remove)等行为是默认的。
npm install taco –save-dev === yarn add taco –dev
npm update –save === yarn upgrade
update(更新) vs upgrade(升级), 赞!upgrade 才是实际做的事!版本号提升时,发生的正是upgrade!
注意: npm update –save 在版本 3.11 中似乎有点问题。
npm install taco@latest –save === yarn add taco
npm install taco –global === yarn global add taco —— 一如既往,请谨慎使用 global 标记。
包和 npm registry 上是一样的。大致而言,Yarn 只是一个新的安装工具,npm 结构和 registry 还是一样的。
npm init === yarn init
npm link === yarn link
npm outdated === yarn outdated
npm publish === yarn publish
npm run === yarn run
npm cache clean === yarn cache clean
npm login === yarn login (logout 同理)
npm test === yarn test
我跳过了一些提醒我们不要使用的内容,如 yarn clean。
yarn licenses ls —— 允许你检查依赖的许可信息。
yarn licenses generate —— 自动创建依赖免责声明 license。
yarn why taco —— 检查为什么会安装 taco,详细列出依赖它的其他包(鸣谢 Olivier Combe)。
Emojis
速度
通过 yarn lockfile 自动实现 shrinkwrap 功能
以安全为中心的设计
npm xmas === NO EQUIVALENT
npm visnup === NO EQUIVALENT
在写这篇文章的时候发现, yarn的run 命令似乎出了点问题,应该会在0.15.2中修复。在这一点上, npm 好多了。以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流。
第一行 Android 代码阅读笔记
Android系统四大组件分别是活动(Activity)、服务(Service)、广播接收器(Broadcast
Receiver)和内容提供器(ContentProvider)。其中活动是所有 Android 应用程序的门面,
凡是在应用中你看得到的东西,都是放在活动中的。而服务就比较低调了,你无法看到
它,但它会一直在后台默默地运行,即使用户退出了应用,服务仍然是可以继续运行的。
广播接收器可以允许你的应用接收来自各处的广播消息,比如电话、短信等,当然你的
应用同样也可以向外发出广播消息。内容提供器则为应用程序之间共享数据提供了可
你可能会对@+id/button_1 这种语法感到陌生,但如果把加号去掉,变成@id/button_1,这你就会觉得有
些熟悉了吧,这不就是在 XML 中引用资源的语法吗,只不过是把 string 替换成了 id。是的,
如果你需要在 XML 中引用一个 id,就使用@id/id_name 这种语法,而如果你需要在 XML 中
定义一个 id,则要使用@+id/id_name 这种语法。
equestWindowFeature(Window.FEATURE_NO_TITLE)的意思就是不在活动中显示
标题栏,注意这句代码一定要在 setContentView()之前执行,不然会报错。
Intent 是 Android 程序中各组件之间进行交互的一种重要方式,它不仅可以指明当前组
件想要执行的动作,还可以在不同组件之间传递数据。Intent 一般可被用于启动活动、启动
服务、以及发送广播等场景,由于服务、广播等概念你暂时还未涉及,那么本章我们的目光
无疑就锁定在了启动活动上面。
Shared mutable state is the root of all evil(共享的可变状态是万恶之源)– Pete Hunt
有人说 Immutable 可以给 React 应用带来数十倍的提升,也有人说 Immutable 的引入是近期 JavaScript 中伟大的发明,因为同期 React 太火,它的光芒被掩盖了。这些至少说明 Immutable 是很有价值的,下面我们来一探究竟。
JavaScript 中的对象一般是可变的(Mutable),因为使用了引用赋值,新的对象简单的引用了原始对象,改变新的对象将影响到原始对象。如 foo={a: 1}; bar=foo; bar.a=2 你会发现此时 foo.a 也被改成了 2。虽然这样做可以节约内存,但当应用复杂后,这就造成了非常大的隐患,Mutable 带来的优点变得得不偿失。为了解决这个问题,一般的做法是使用 shallowCopy(浅拷贝)或 deepCopy(深拷贝)来避免被修改,但这样做造成了 CPU 和内存的浪费。
Immutable 可以很好地解决这些问题。
Immutable Data 就是一旦创建,就不能再被更改的数据。对 Immutable 对象的任何修改或添加删除操作都会返回一个新的 Immutable 对象。Immutable 实现的原理是 Persistent Data Structure(持久化数据结构),也就是使用旧数据创建新数据时,要保证旧数据同时可用且不变。同时为了避免 deepCopy 把所有节点都复制一遍带来的性能损耗,Immutable 使用了 Structural Sharing(结构共享),即如果对象树中一个节点发生变化,只修改这个节点和受它影响的父节点,其它节点则进行共享。请看下面动画:
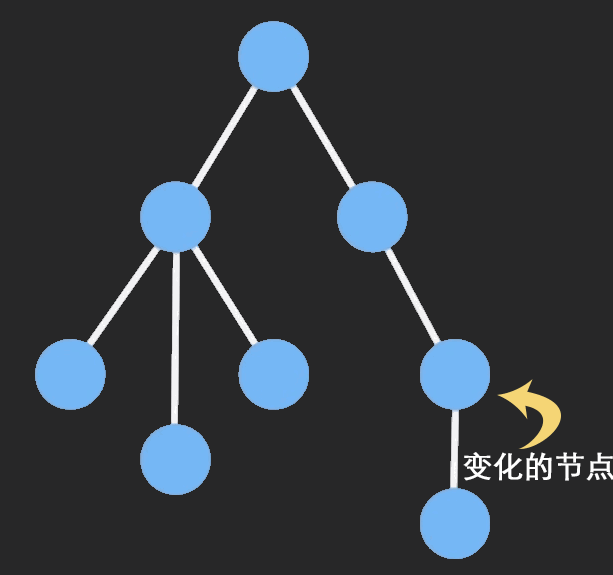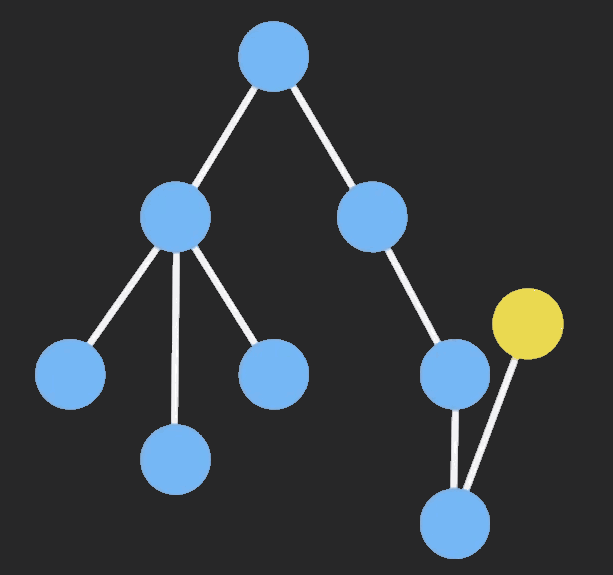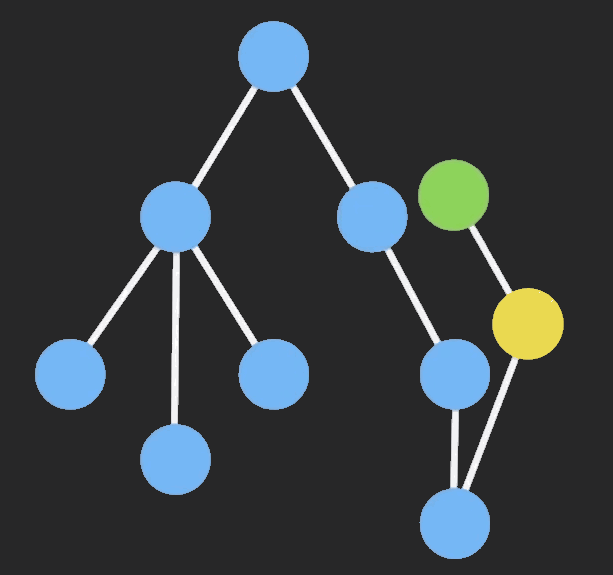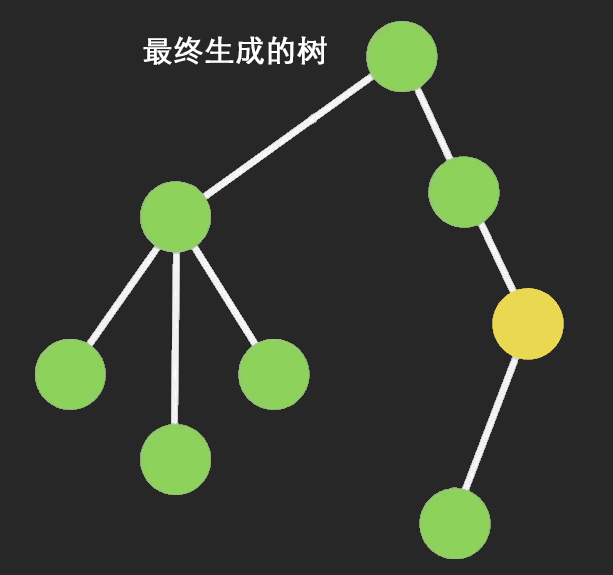
目前流行的 Immutable 库有两个:
Facebook 工程师 Lee Byron 花费 3 年时间打造,与 React 同期出现,但没有被默认放到 React 工具集里(React 提供了简化的 Helper)。它内部实现了一套完整的 Persistent Data Structure,还有很多易用的数据类型。像 Collection、List、Map、Set、Record、Seq。有非常全面的map、filter、groupBy、reducefind函数式操作方法。同时 API 也尽量与 Object 或 Array 类似。
其中有 3 种最重要的数据结构说明一下:(Java 程序员应该最熟悉了)
Map:键值对集合,对应于 Object,ES6 也有专门的 Map 对象
List:有序可重复的列表,对应于 Array
Set:无序且不可重复的列表
与 Immutable.js 学院派的风格不同,seamless-immutable 并没有实现完整的 Persistent Data Structure,而是使用 Object.defineProperty(因此只能在 IE9 及以上使用)扩展了 JavaScript 的 Array 和 Object 对象来实现,只支持 Array 和 Object 两种数据类型,API 基于与 Array 和 Object 操持不变。代码库非常小,压缩后下载只有 2K。而 Immutable.js 压缩后下载有 16K。
下面上代码来感受一下两者的不同:
1 | // 原来的写法 |
可变(Mutable)数据耦合了 Time 和 Value 的概念,造成了数据很难被回溯。
比如下面一段代码:1
2
3
4
5function touchAndLog(touchFn) {
let data = { key: 'value' };
touchFn(data);
console.log(data.key); // 猜猜会打印什么?
}
在不查看 touchFn 的代码的情况下,因为不确定它对 data 做了什么,你是不可能知道会打印什么(这不是废话吗)。但如果 data 是 Immutable 的呢,你可以很肯定的知道打印的是 value。
Immutable.js 使用了 Structure Sharing 会尽量复用内存,甚至以前使用的对象也可以再次被复用。没有被引用的对象会被垃圾回收。1
2
3
4
5
6
7
8
9import { Map} from 'immutable';
let a = Map({
select: 'users',
filter: Map({ name: 'Cam' })
})
let b = a.set('select', 'people');
a === b; // false
a.get('filter') === b.get('filter'); // true
上面 a 和 b 共享了没有变化的 filter 节点。
因为每次数据都是不一样的,只要把这些数据放到一个数组里储存起来,想回退到哪里就拿出对应数据即可,很容易开发出撤销重做这种功能。
后面我会提供 Flux 做 Undo 的示例。
传统的并发非常难做,因为要处理各种数据不一致问题,因此『聪明人』发明了各种锁来解决。但使用了 Immutable 之后,数据天生是不可变的,并发锁就不需要了。
然而现在并没什么卵用,因为 JavaScript 还是单线程运行的啊。但未来可能会加入,提前解决未来的问题不也挺好吗?
Immutable 本身就是函数式编程中的概念,纯函数式编程比面向对象更适用于前端开发。因为只要输入一致,输出必然一致,这样开发的组件更易于调试和组装。
像 ClojureScript,Elm 等函数式编程语言中的数据类型天生都是 Immutable 的,这也是为什么 ClojureScript 基于 React 的框架 — Om 性能比 React 还要好的原因。
No Comments
No Comments
这点是我们使用 Immutable.js 过程中遇到最大的问题。写代码要做思维上的转变。
虽然 Immutable.js 尽量尝试把 API 设计的原生对象类似,有的时候还是很难区别到底是 Immutable 对象还是原生对象,容易混淆操作。
Immutable 中的 Map 和 List 虽对应原生 Object 和 Array,但操作非常不同,比如你要用 map.get(‘key’) 而不是 map.key,array.get(0) 而不是 array[0]。另外 Immutable 每次修改都会返回新对象,也很容易忘记赋值。
当使用外部库的时候,一般需要使用原生对象,也很容易忘记转换。
下面给出一些办法来避免类似问题发生:
使用 Flow 或 TypeScript 这类有静态类型检查的工具
约定变量命名规则:如所有 Immutable 类型对象以 $$ 开头。
使用 Immutable.fromJS 而不是 Immutable.Map 或 Immutable.List 来创建对象,这样可以避免 Immutable 和原生对象间的混用。
Immutable.is
两个 immutable 对象可以使用 === 来比较,这样是直接比较内存地址,性能最好。但即使两个对象的值是一样的,也会返回 false:1
2
3let map1 = Immutable.Map({a:1, b:1, c:1});
let map2 = Immutable.Map({a:1, b:1, c:1});
map1 === map2; // false
为了直接比较对象的值,immutable.js 提供了 Immutable.is 来做『值比较』,结果如下:1
Immutable.is(map1, map2); // true
Immutable.is 比较的是两个对象的 hashCode 或 valueOf(对于 JavaScript 对象)。由于 immutable 内部使用了 Trie 数据结构来存储,只要两个对象的 hashCode 相等,值就是一样的。这样的算法避免了深度遍历比较,性能非常好。
后面会使用 Immutable.is 来减少 React 重复渲染,提高性能。
另外,还有 mori、cortex 等,因为类似就不再介绍。
ES6 中新加入的 Object.freeze 和 const 都可以达到防止对象被篡改的功能,但它们是 shallowCopy 的。对象层级一深就要特殊处理了。
这个 Cursor 和数据库中的游标是完全不同的概念。
由于 Immutable 数据一般嵌套非常深,为了便于访问深层数据,Cursor 提供了可以直接访问这个深层数据的引用。1
2
3
4
5
6
7
8
9
10
11
12
13import Immutable from 'immutable';
import Cursor from 'immutable/contrib/cursor';
let data = Immutable.fromJS({ a: { b: { c: 1 } } });
// 让 cursor 指向 { c: 1 }
let cursor = Cursor.from(data, ['a', 'b'], newData => {
// 当 cursor 或其子 cursor 执行 update 时调用
console.log(newData);
});
cursor.get('c'); // 1
cursor = cursor.update('c', x => x + 1);
cursor.get('c'); // 2
与 React 搭配使用,Pure Render
熟悉 React 的都知道,React 做性能优化时有一个避免重复渲染的大招,就是使用 shouldComponentUpdate(),但它默认返回 true,即始终会执行 render() 方法,然后做 Virtual DOM 比较,并得出是否需要做真实 DOM 更新,这里往往会带来很多无必要的渲染并成为性能瓶颈。
当然我们也可以在 shouldComponentUpdate() 中使用使用 deepCopy 和 deepCompare 来避免无必要的 render(),但 deepCopy 和 deepCompare 一般都是非常耗性能的。
Immutable 则提供了简洁高效的判断数据是否变化的方法,只需 === 和 is 比较就能知道是否需要执行 render(),而这个操作几乎 0 成本,所以可以极大提高性能。修改后的 shouldComponentUpdate 是这样的:
1 | import { is } from 'immutable'; |
使用 Immutable 后,如下图,当红色节点的 state 变化后,不会再渲染树中的所有节点,而是只渲染图中绿色的部分: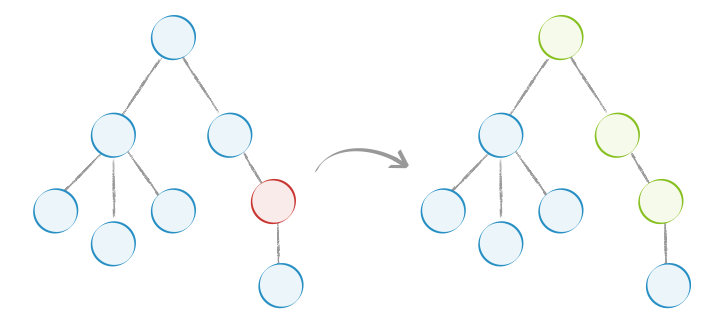
你也可以借助 React.addons.PureRenderMixin 或支持 class 语法的 pure-render-decorator 来实现。
setState 的一个技巧
React 建议把 this.state 当作 Immutable 的,因此修改前需要做一个 deepCopy,显得麻烦:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import '_' from 'lodash';
const Component = React.createClass({
getInitialState() {
return {
data: { times: 0 }
}
},
handleAdd() {
let data = _.cloneDeep(this.state.data);
data.times = data.times + 1;
this.setState({ data: data });
// 如果上面不做 cloneDeep,下面打印的结果会是已经加 1 后的值。
console.log(this.state.data.times);
}
}
使用 Immutable 后:1
2
3
4
5
6
7
8
9
10getInitialState() {
return {
data: Map({ times: 0 })
}
},
handleAdd() {
this.setState({ data: this.state.data.update('times', v => v + 1) });
// 这时的 times 并不会改变
console.log(this.state.data.get('times'));
}
上面的 handleAdd 可以简写成:1
2
3
4
5handleAdd() {
this.setState(({data}) => ({
data: data.update('times', v => v + 1) })
});
}
由于 Flux 并没有限定 Store 中数据的类型,使用 Immutable 非常简单。
现在是实现一个类似带有添加和撤销功能的 Store:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import { Map, OrderedMap } from 'immutable';
let todos = OrderedMap();
let history = []; // 普通数组,存放每次操作后产生的数据
let TodoStore = createStore({
getAll() { return todos; }
});
Dispatcher.register(action => {
if (action.actionType === 'create') {
let id = createGUID();
history.push(todos); // 记录当前操作前的数据,便于撤销
todos = todos.set(id, Map({
id: id,
complete: false,
text: action.text.trim()
}));
TodoStore.emitChange();
} else if (action.actionType === 'undo') {
// 这里是撤销功能实现,
// 只需从 history 数组中取前一次 todos 即可
if (history.length > 0) {
todos = history.pop();
}
TodoStore.emitChange();
}
});
Redux 是目前流行的 Flux 衍生库。它简化了 Flux 中多个 Store 的概念,只有一个 Store,数据操作通过 Reducer 中实现;同时它提供更简洁和清晰的单向数据流(View -> Action -> Middleware -> Reducer),也更易于开发同构应用。目前已经在我们项目中大规模使用。
由于 Redux 中内置的 combineReducers 和 reducer 中的 initialState 都为原生的 Object 对象,所以不能和 Immutable 原生搭配使用。
幸运的是,Redux 并不排斥使用 Immutable,可以自己重写 combineReducers 或使用 redux-immutablejs 来提供支持。
上面我们提到 Cursor 可以方便检索和 update 层级比较深的数据,但因为 Redux 中已经有了 select 来做检索,Action 来更新数据,因此 Cursor 在这里就没有用武之地了。
Immutable 可以给应用带来极大的性能提升,但是否使用还要看项目情况。由于侵入性较强,新项目引入比较容易,老项目迁移需要评估迁移。对于一些提供给外部使用的公共组件,最好不要把 Immutable 对象直接暴露在对外接口中。
如果 JS 原生 Immutable 类型会不会太美,被称为 React API 终结者的 Sebastian Markbåge 有一个这样的提案,能否通过现在还不确定。不过可以肯定的是 Immutable 会被越来越多的项目使用。
资源
Lee Byron - Immutable Data and React
Immutable Data Structures and JavaScript
Android开发环境就不记录了,由于有了android studio搭建起来也很容易,网上也有很多,这里就不说了。
1、一个Activity就是一个类,并且这个类继承Activity基类;
2、需要复写onCreate方法(第一次调用Activity就会调用);
3、每个Activity都需要在AndroidMainFest(清单)文件中进行配置;
4、为Activity添加必要组件;
5、setContentView()使用;
6、findViewById()使用;
7、在布局文件中Android:”@+id/idName”和没有+号区别,还有在R.java中文件生成的引用名称的使用区别?(有待以后解答)
第一个原生应用的显示效果:
1、Component name(下一个启动activity的名字)
2、Action(个人理解对下个activity的指令(例如:ACTION_CALL))
3、Data(数据)
4、Category
5、Extras(键值对)
6、Flasgs
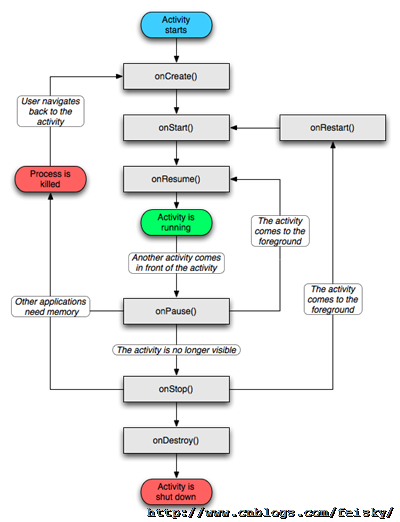
1、onCreate:Activity第一被创建被调用
2、onStart:Activity能被看到被调用
3、onResume:Activity能够获取用户焦点时被调用
4、onPause:应用程序启用了另外一个acitity(来电话就会调用pause,当前数据保存)
5、onStop:当前Activity不可见被调用;(对话框不会调用上一个activity的onStop)
6、onDestory:finish(),系统资源不够用;
7、onRestart:返回时替换onCreate被调用
栈的概念很好理解,已经理解!
好久没写博客了,今天给大家推荐一款录屏工具!
1 | <video width="352" height="264" controls autobuffer> |
对于Opera浏览器,您可以参阅这篇上周才发表的文章“Everything you need to know about HTML5 video and audio”
对于IE浏览器,那还不知道要等到猴年马月才等到支持HTML5 video标签的时候。然而,广大劳动人民的智慧是无穷无尽的,广大开发人员的智慧也会无穷无尽的。国外领先的web开拓者们通过js,已经实现了可以让各个主流浏览器支持video标签的方法。
方法很简单,只要调用一段js,就可以让主流浏览器实现video标签的视频播放。
此项目已经放到Google code上,您可以点击这里查看。
使用方法:
要想让主流浏览器都支持HTML5标签,使用非常简单,只要链接一个js文件就可以了。所以,只要您的页面上(头部或底部)有这么段代码:1
<script src="http://html5media.googlecode.com/svn/trunk/src/html5media.min.js"></script>
就可以了。
对于HTML部分,使用类似下面:1
<video src="video.mp4" width="320" height="240" controls autobuffer></video>
是不是很简单啊!
为了演示效果,我就直接把此js以及video标签签到这篇文章里,您将会在下面看到这段10秒钟的关于猫咪的视频,您可以切换IE或是Firefox或是chrome或是Safari观看(界面有差别的哦~~)。
更新于2016-06-03
由于下面2个资源大大拖慢了网页的加载速度,因此,今日起博客文章不直接呈现效果,大家可以点击下面的demo链接体验。1
2<script src="http://html5media.googlecode.com/svn/trunk/src/html5media.min.js"></script>
<video src="http://www.zhangxinxu.com/study/media/cat.mp4" width="352" height="264" controls autobuffer></video>
当加载完毕,点击播放按钮,就可以看到视频播放了。
或者您也可以狠狠地点击这里:HTML5 video多浏览器支持测试demo
实现的原理大致是使用了flash技术,使用flash播放器嵌入视频的方式,使得IE及Firefox支持video标签。这个播放器称为flowplayer,具体我也不是很了解。
目前,这种多浏览器支持方法所支持的视频格式有限,为mp4和ogv格式,否则视频可能不会播放。
您可能会遇到这样的问题:我明明链接的是mp4格式的文件啊,为什么在IE及Firefox下有问题。如果您遇到的问题是在这两个浏览器下视频不播放,或是播放时只有声音而没有图像,而在chrome浏览器或是Safari下良好,则您可能要仔细您mp4文件的编码格式了。
对于编码,我不在行,好像是视频要存储为h.264文件,不要问我是什么东西,我也不知道,这可能还要靠您自己解决了。
最后,百无聊赖,先上一张Safari浏览器下的截图,原因是,Safari下的播放器真是卡哇伊。
总的来说,四种JOIN的使用/区别可以描述为:
left join 会从左表(shop)那里返回所有的记录,即使在右表(sale_detail)中没有匹配的行。
right outer join 右连接,返回右表中的所有记录,即使在左表中没有记录与它匹配
full outer join 全连接,返回左右表中的所有记录在表中存在至少一个匹配时,inner join 返回行。 关键字inner可省略。
具体可以看stackoverflow上,Difference between Inner Join & Full join这个问题,说得蛮清楚的,我就搬运一下这个问题的答案好了。
一共有三种OUTER JOIN:
关键字OUTER是可选择的,取决于具体语言,在实现上它们都是遵循标准的,因此FULL JOIN和FULL OUTER JOIN是一样的。
接着将以简化的数据集来说明这些JOIN语句。考虑有如下两个数据集,注意到有些元素在A中有,在B中没有,反过来也是。
1 | Set "A" Set "B" |
现在执行如下SQL语句(左连接,LEFT OUTER JOIN):
1 | SELECT * FROM A LEFT OUTER JOIN B ON AA = BB |
将会得到如下的结果(空白的元素表示NULL):
1 | AA BB |
左连接(LEFT OUTER JOIN)会输出左边的表中的所有结果,如果右边的表中有相应项,则会输出,否则为NULL
因此,如果要找出在AA(左边的表)中有,而在BB(右边的表)中没有的数据项,可以使用如下的SQL语句:1
2SELECT * FROM A LEFT OUTER JOIN B ON AA = BB
WHERE BB is NULL
如果使用右连接,结果将会输出BB中所有的数据项和AA中相应的匹配项(注意你现在是获取了右边的表中的所有数据项):1
2
3
4
5
6
7
8SELECT * FROM A RIGHT OUTER JOIN B ON AA = BB
AA BB
-------- --------
Item 3 Item 3
Item 4 Item 4
Item 5
Item 6
如果想要取得所有的元素项,则可以使用FULL JOIN:1
2
3
4
5
6
7
8
9
10
11
12
13SELECT * FROM A FULL JOIN B ON AA = BB
AA BB
-------- --------
Item 1 <-----+
Item 2 |
Item 3 Item 3 |
Item 4 Item 4 |
Item 5 +--- empty holes are NULL's
Item 6 |
^ |
| |
+---------------------+
再次注意,缺失的数据项的值是NULL。
INNER JOIN跟JOIN是一样的,一般INNER关键字可以省略。INNER JOIN将只会返回相匹配的元素项,即不会返回结果为NULL的数据项。1
2
3
4
5
6SELECT * FROM A INNER JOIN B ON AA = BB
AA BB
-------- --------
Item 3 Item 3
Item 4 Item 4
最后还有一个CROSS JOIN,笛卡儿积,将会返回A中每个元素分别匹配B中所有元素的结果,即N*M组合。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20SELECT * FROM A CROSS JOIN B
AA BB
-------- --------
Item 1 Item 3 ^
Item 1 Item 4 +--- A中第一个元素, 匹配B中所有元素
Item 1 Item 5 |
Item 1 Item 6 v
Item 2 Item 3 ^
Item 2 Item 4 +--- A中第二个元素, 匹配B中所有元素
Item 2 Item 5 |
Item 2 Item 6 v
Item 3 Item 3 ... and so on
Item 3 Item 4
Item 3 Item 5
Item 3 Item 6
Item 4 Item 3
Item 4 Item 4
Item 4 Item 5
Item 4 Item 6
这边也有一张图清楚的说明了每个JOIN操作。建议把上面的内容浏览一边后,再好好看下这张图片,相信对JOIN的操作应该就完全明白了。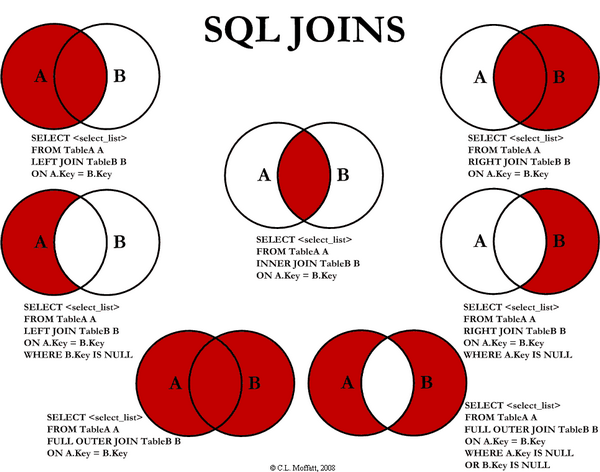
缺失模块。
1、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
2、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: true
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true